ShapBotとは?Gemini EnterpriseのWeb検索にも関係するAIクローラーの正体
アクセスログに「ShapBot」というユーザーエージェント名が残っていて、何のクローラーなのか気になった方もいるかもしれません。
ShapBotは、AIエージェント向けのWeb検索インフラを提供する「Parallel Web Systems」が運営するクローラーです。単なる巡回ボットというより、ParallelのWeb APIでサイトを発見・インデックスするためのクローラーであり、GoogleのGemini Enterprise Agent PlatformにおけるWeb検索グラウンディングとも関係しています。
この記事では、ShapBotの正体・運営元・Gemini Enterpriseとの関係・Shap-Userとの違い・robots.txtでの制御方法まで、一次情報をもとに解説します。
この記事でわかること|📖:約5分
- ShapBotとは何か、どの企業が運営しているか
- ShapBotがGemini Enterpriseとどう関係しているのか
- ShapBotとShap-Userの違い
- robots.txtで許可・拒否する具体的な方法
ShapBotとは何か
ShapBotは、Parallel Web Systemsが開発・運営するWebクローラーです。ユーザーエージェント文字列は以下のとおりです。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ShapBot/0.1.0ShapBotの役割は、公開されているWebページを発見・巡回し、ParallelのWeb APIで利用できる検索インデックスを構築・維持することです。
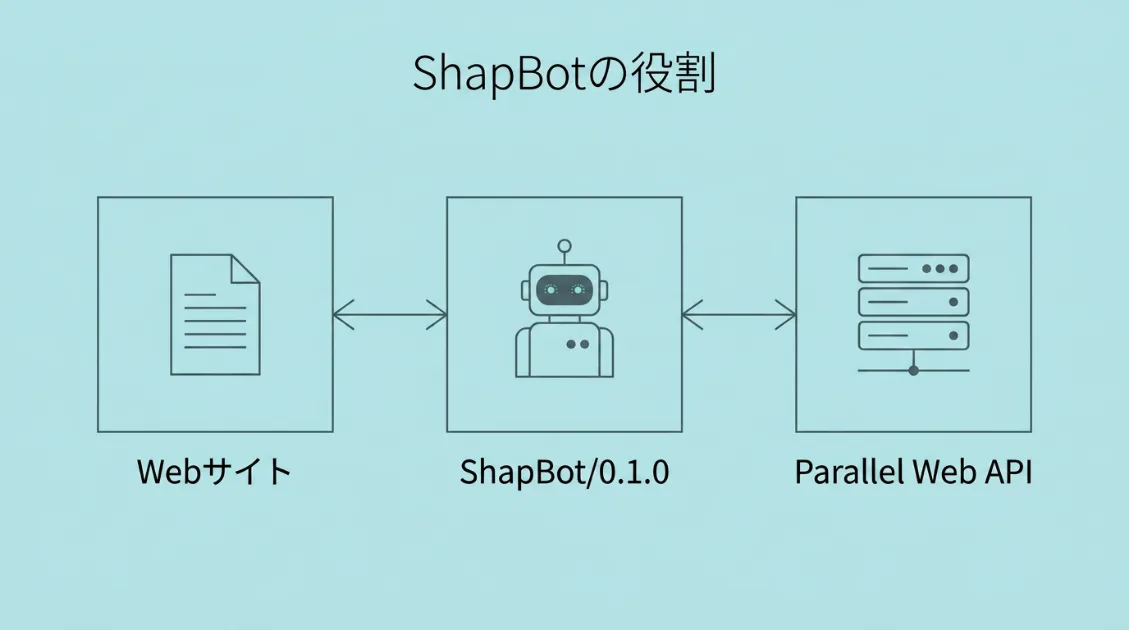
つまりは、ShapBotは単なるアクセス解析上の「謎のbot」ではなく、AIエージェント向けの検索基盤を支えるクローラーのひとつです。OpenAIのGPTBotやAnthropicのClaudeBotと同じく、AI時代のWebクローラーとしてサイト運営者が把握しておきたい存在だと言えます。
また、Parallelのクローラーには、自動巡回用の「ShapBot」と、ユーザー操作に起因してアクセスする「Shap-User」があります。この違いについては後述します。
なぜ今ShapBotが重要なのか
ShapBotが注目される理由は、Parallelの検索基盤がAIエージェントの「目」として機能し始めているからです。
2025年以降、ChatGPTやGeminiのようなAIは、単に学習済みの知識だけで質問に答えるのではなく、必要に応じてWeb上の情報を検索し、その結果をもとに回答を生成するようになってきました。このように、外部情報を参照して回答の根拠にする仕組みは「グラウンディング」と呼ばれます。
Parallelは、このグラウンディングに使われるWeb検索インフラのひとつです。Google Cloudの公式ドキュメントでも、Gemini Enterprise Agent PlatformでParallelの検索APIを使い、公開WebデータをもとにGeminiの回答をグラウンディングできることが説明されています。
また、Parallel Web Systemsは2026年4月に1億ドルのシリーズB調達を行い、評価額は20億ドルに達したと報じられています。AIエージェント向けのWeb検索APIを提供する企業として、急速に存在感を高めていることがわかります。
ShapBotは、そのParallelの検索インデックスを構築・維持するためのクローラーです。なので、「ShapBotに読まれる」ということは、Parallelの検索基盤にサイトが発見・登録される可能性があるということです。
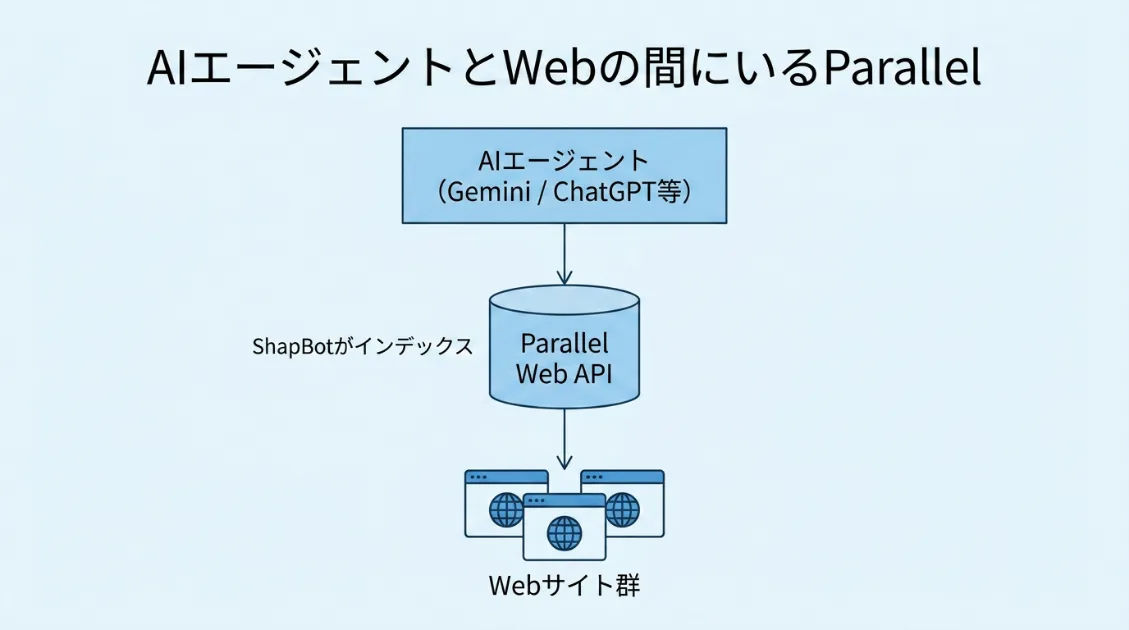
GoogleやOpenAIの公式クローラーほど知名度はありませんが、AIエージェントがWebを参照する経路が多様化するなかで、ShapBotはサイト運営者が把握しておきたい入口のひとつになりつつあります。
運営元Parallel Web Systemsとは
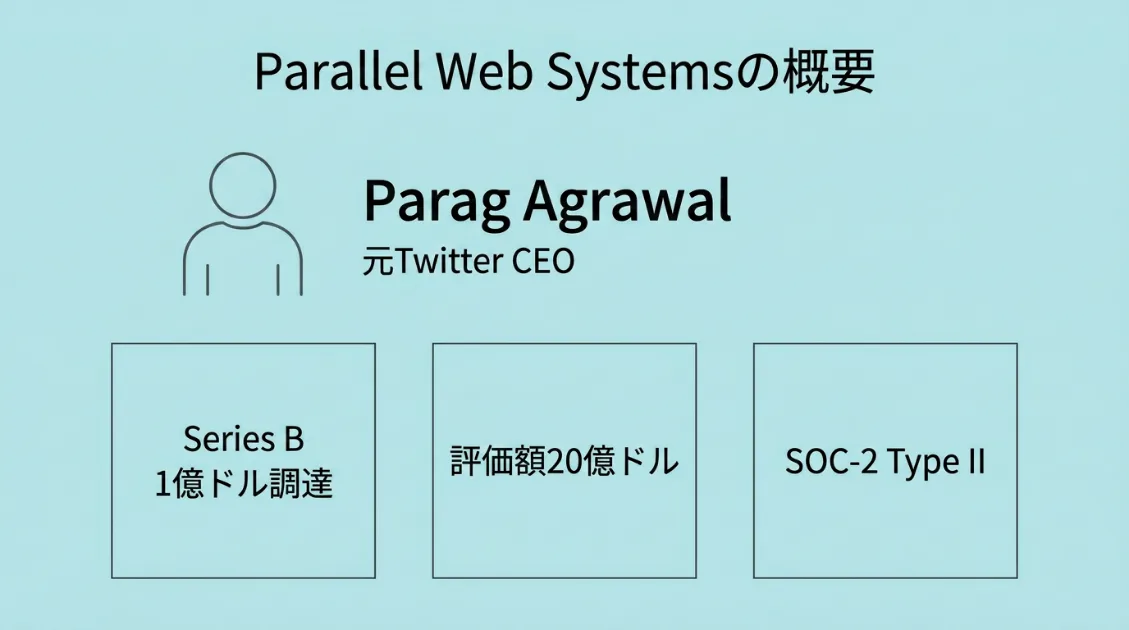
Parallel Web Systemsは、元Twitter(現X)CEOのParag Agrawalが創業した、AIエージェント向けのWeb検索インフラ企業です。
従来の検索エンジンが「人間がクリックするためのリンク一覧」を返すのに対し、ParallelはAIエージェントがそのまま利用しやすい形で、Web上の情報を検索・取得・整理するためのAPIを提供しています。
Reutersの報道でも、ParallelはAIシステムがリアルタイムにWebを検索し、タスクを実行するためのAPIを構築している企業として紹介されています。
資金調達の面でも急成長しています。2025年11月にはシリーズAで1億ドルを調達し、評価額は7.4億ドルに達しました。その後、2026年4月にはSequoia Capital主導のシリーズBでさらに1億ドルを調達し、評価額は20億ドルに達したと報じられています。
提供するサービスは、Web検索、ディープリサーチ、データセット作成、Webエンリッチメント、Webモニタリングなど複数あります。Parallel公式サイトでも、AIエージェントにWebコンテキストを与える検索ツールや、Web上の変化を継続的に監視する機能が紹介されています。
また、ParallelはMCP(Model Context Protocol)との連携にも力を入れており、AIエージェントが外部ツールとしてParallelの機能を使える設計になっています。公式サイト上でもSOC 2 Type II認証済みであることが示されており、エンタープライズ向けの信頼性も意識されたサービスだと言えます。
Gemini Enterprise Agent PlatformとShapBotの関係
ShapBotを理解するうえで重要なのが、GoogleのGemini Enterprise Agent Platformとの関係です。
Gemini Enterprise Agent Platformには、AIエージェントが外部のWeb情報を参照し、その内容をもとに回答を生成する「グラウンディング」機能があります。そのWeb検索の選択肢のひとつとして、ParallelのSearch APIを使った「Grounding with Parallel web search」が用意されています。
Google公式ドキュメントでは、Parallel Web Systemsの検索APIが、大規模言語モデルのグラウンディング向けに最適化された公開Webデータへのアクセスを提供すると説明されています。
さらに、Webサイト運営者にとって重要なのは下記の点です。
ShapBotをrobots.txtで拒否しているWebページは、Gemini Enterprise Agent PlatformにおけるParallel経由のグラウンディングには使用されません。
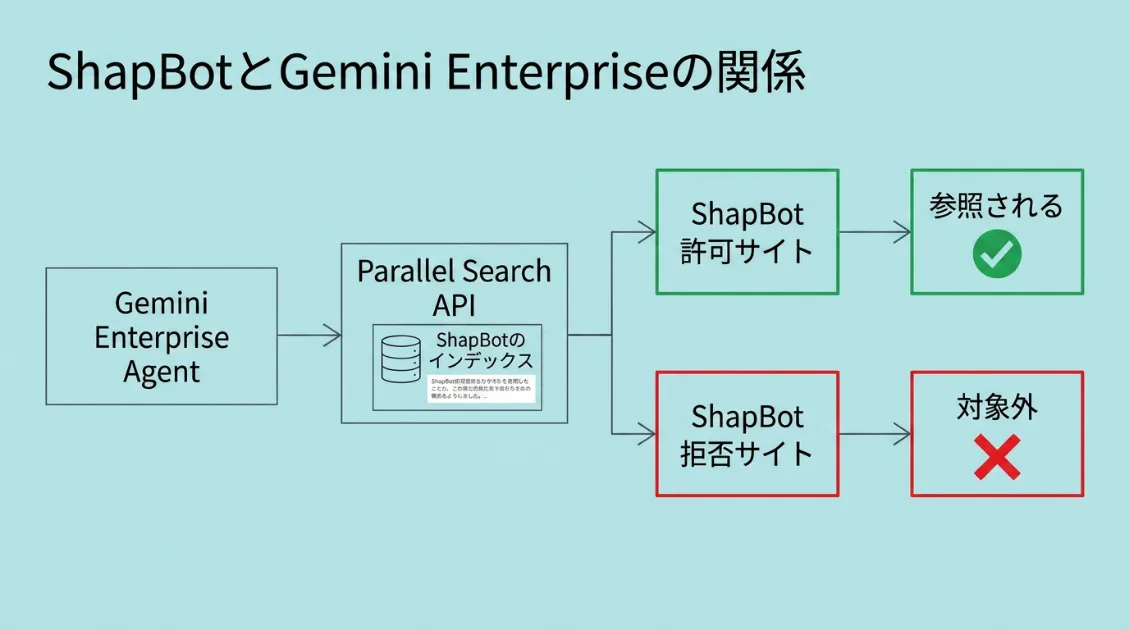
つまりは、robots.txtでShapBotをDisallowにしているサイトは、Gemini EnterpriseのエージェントがParallel経由でそのサイトのコンテンツを参照する経路のひとつを閉じていることになります。AIに引用・参照される機会を、意図せず減らしている可能性があります。
ですが、これはGemini Enterprise Agent Platformの「Parallel web search」に関する話。通常のGoogle検索、Googlebot、Google-Extended、一般向けのGeminiアプリとは別の経路なので、混同しないよう注意が必要です。
なお、Google公式ドキュメント上では、この機能はPreviewとして提供されています。今後仕様や対応範囲が変わる可能性もあります。
ShapBotとShap-Userの違い
Parallel Web Systemsが公開しているユーザーエージェントには、「ShapBot」と「Shap-User」があります。名前が似ているため、混同しないよう整理しておきます。
| 名称 | ユーザーエージェント | 役割 | 自動巡回 |
|---|---|---|---|
| ShapBot | ShapBot/0.1.0 | Parallelの検索インデックス構築・維持 | あり |
| Shap-User | Shap-User/0.1.0 | ユーザー操作に起因するアクセス | なし |
ShapBotは、自動的にWebを巡回してParallelの検索インデックスを構築・維持するためのクローラーです。対してShap-Userは、実際のユーザーがParallelのサービスやAPIを経由しWebコンテンツにアクセスしたときに使われるユーザーエージェントです。
Parallel公式ドキュメントでは、Shap-Userは自動的なWeb巡回には使われず、コンテンツ所有者にユーザー起因のアクセスであることを見えるようにするためのものだと説明されています。なので、robots.txtで自動巡回を制御したい場合は、基本的にShapBotを対象にします。
robots.txtでShapBotを制御する方法
ShapBotはrobots.txtによる制御に対応しています。許可・拒否どちらも設定できます。
許可する場合
Parallel経由の検索インデックスに入り、Gemini Enterprise Agent PlatformのParallel web searchによるグラウンディング対象になる可能性を残したい場合は、以下のように設定します。
User-agent: ShapBot
Allow: /拒否する場合
Parallelの検索基盤へのデータ提供を望まない場合は、以下のように設定します。ただし、拒否するとParallel経由の検索結果や、Gemini Enterprise Agent PlatformにおけるParallel web searchのグラウンディングで参照されにくくなる可能性があります。
User-agent: ShapBot
Disallow: /IPアドレスでの確認・制御
Parallelは公式ドキュメントでShapBotのIPアドレスリストを公開しています。WAFやCDN、サーバー側でアクセス元を確認・制御したい場合は、以下のURLから最新のIPリストを取得できます。
https://docs.parallel.ai/resources/shapbot.jsonrobots.txtはクローラーに対して巡回方針を伝えるための設定です。一方で、IPアドレスによる制御は、WAF・CDN・サーバー側で実際のアクセスを許可または拒否するために使います。ShapBotを許可したい場合でも、ユーザーエージェント名だけで判断せず、必要に応じて公式IPリストと照合するのが安全です。
各クローラーの詳細については、AIクローラーの種類と一覧もあわせて参照してください。
AI観測ラボでの観測
AI観測ラボでも、2026年6月の観測期間中に ShapBot/0.1.0 による当サイトへのアクセスをSSHログ上で確認しました。現時点では件数や巡回傾向を断定できる段階ではありませんが、今後も継続して観測していきます。
まとめ
ShapBotは、AIエージェント向けWeb検索インフラを提供するParallel Web Systemsのクローラーです。単なるデータ収集ボットではなく、Parallelの検索インデックスを構築・維持する役割を持ち、Gemini Enterprise Agent PlatformのWebグラウンディングとも関係する存在です。
ポイントを整理するとこうなります。
- ShapBotはParallel Web Systemsが運営するインデックス用クローラー
- 運営元のParallelは元Twitter CEOが創業したAIエージェント向けWeb検索インフラ企業
- Parallel Search APIは、Gemini Enterprise Agent Platformの外部グラウンディングプロバイダーとして利用できる
- ShapBotをDisallowにすると、Parallel経由の検索やGemini Enterpriseのグラウンディング対象から外れる可能性がある
- 自動巡回用のShapBotと、ユーザー起因アクセス用のShap-Userは別物
- robots.txtと公式IPリストを確認しながら制御できる
AIエージェントがWebを参照する経路は、GooglebotやGPTBotだけではありません。ShapBotのような新しいクローラーが増えるにつれて、どのクローラーを許可してどれを拒否するかという判断が、サイト運営者に求められる場面は増えていきそうです。AI観測ラボでは、引き続きこうしたAIクローラーの動きを観測していきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


