AIクローラーとは?GPTBot・ClaudeBot・PerplexityBotの違いと確認方法

サーバーログに llms.txt という文字列が現れるようになったのは、2024年後半あたりからです。「AIにサイト構造を伝えるためのファイル」として注目され、設置するサイトも徐々に増えてきました。
一方で、「実際にAIクローラーが llms.txt を読んでいるのか」を、サーバーログベースで検証した日本語記事はほとんど見当たりません。
AI観測ラボでは、2026年1月にllms.txtを設置し、サーバーログを継続観測しています。設置直後から約6週間、誰も読まない期間が続きました。その後、3月にAI-Observatory/1.0、5月にGPTBot/1.3とGooglebotが初めて取得しています。
「置けば読まれる」という期待と、実測のギャップを一次ログで整理します。
この記事でわかること|📖:約9分
- llms.txtが何で、robots.txt・sitemapと何が違うのか
- 設置から6週間誰も読まなかった実測ログと、最初に読んだ3つのクローラー
- PerplexityBot・ClaudeBotが読まなかった理由(3つの巡回型仮説)
- それでも設置する意味と、WordPressでのコピペ用テンプレート
llms.txtとは何か
llms.txtは、サイトの内容をAI(大規模言語モデル・LLM)に伝えるためのMarkdown形式のテキストファイルです。2024年9月、Answer.AIのJeremy Howard氏によって提唱されました。まだIETFやW3Cの正式な規格ではありませんが、Anthropic・Cloudflare・Stripeなどが導入を進めています。
中身は広告やナビがない、クリーンなMarkdown。サイト概要と、重要ページへのリンクと一行説明だけで構成します。
# AI観測ラボ | AI時代の検索の変化を観測する
> AIクローラーの動きをサーバーログで観測し、AIに引用されるサイトの条件を実測で解明するメディア
## Blog Articles
- [robots.txt完全ガイド](/robots-txt-ai-crawler-complete/) - 156件の実測ログで分かった設計の正解
- [AIクローラーとは?](/ai-crawler/) - 3つの役割と動きの違い
- [AI観測ラボ Trackerプラグイン](/wp-content/plugins/ai-kansoku-lab-tracker/) - WordPressでAI訪問を可視化
## About
- [AI観測ラボについて](/about/) - 運営と観測の目的
## Optional
- [お問い合わせ](/contact/)
llms.txtとrobots.txtの違い
| robots.txt | llms.txt | |
|---|---|---|
| 目的 | クローラーの巡回を制御する | AIにサイト内容を伝える |
| 役割 | 許可・拒否 | 案内・説明 |
| 形式 | 専用ルール | Markdown |
| 標準化 | RFC 9309 国際標準 | 提案段階 |
| 効力 | 多くが遵守 | 読むかどうかはクローラー次第 |
OBSERVATION CHECK
あなたのサイトのllms.txt、誰が読んでるか知ってますか?
この記事のログのように、llms.txtは置いてもすぐには読まれません。
AI Kansoku Lab Trackerなら、GPTBotがllms.txtを読んだ瞬間をWordPress管理画面で検知できます。
GA4では見えないAIの動きを、設置したその日から観測できます。
robots.txtは「守衛」、llms.txtは「案内パンフレット」。両方置くのが正解です。

AIクローラーは実際にllms.txtを読んでいるのか——設置から5ヶ月の実測ログ
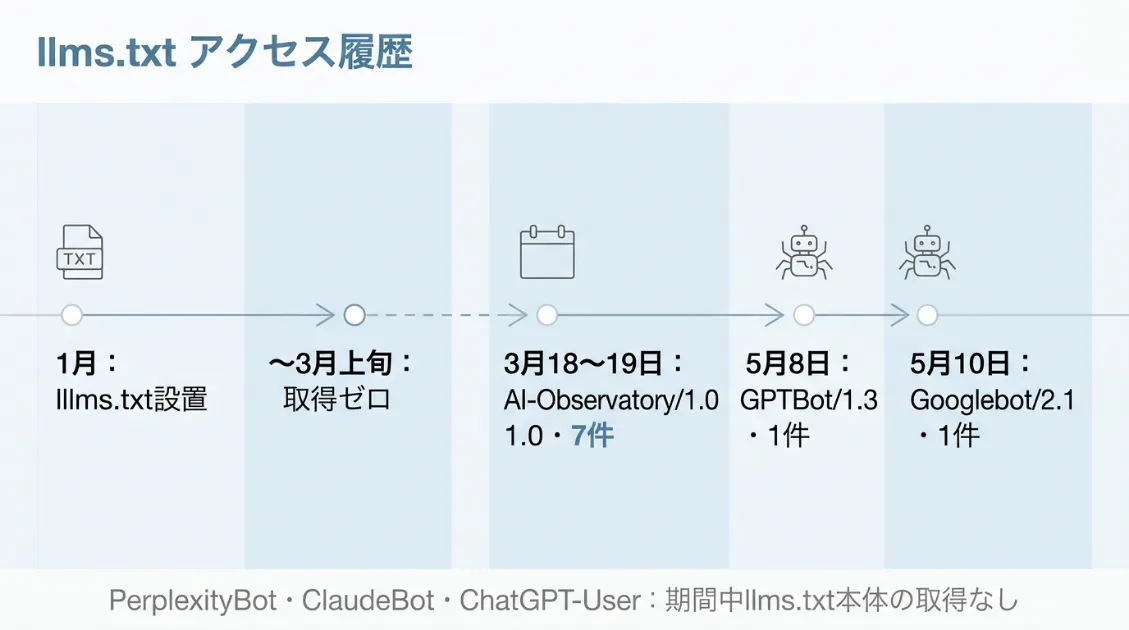
AI観測ラボでは2026年1月にllms.txtを設置。ファイル本体 /llms.txt へのアクセスを全件抽出しました。
設置から約6週間、誰も読まなかった【AI実験室 #04】
1月設置〜3月上旬まで、llms.txt本体へのアクセスはゼロでした。7日間のログをまとめた検証記事でも「AIクローラーは誰も読んでいなかった」と報告しています。
置けばすぐ読まれるわけではない。これが最初の実測結果です。
3月:AI-Observatory/1.0が最初に取得
3月18日〜19日にかけて AI-Observatory/1.0 が7件集中して取得。IPはすべてAWSバージニア北部。特徴は、記事ページには一切来ず、llms.txtだけを単体で取得する動きでした。
5月:GPTBotとGooglebotが取得
5月8日 07:40に GPTBot/1.3 が1件取得。リファラにトップページが残っており、トップを起点にllms.txtへ到達していました。同じIPは前後に /llms-txt-guide/ や検証記事も読んでおり、llms.txtという概念自体を収集していた可能性があります。
5月10日 08:08には Googlebot/2.1 が1件取得。Googleがファイルの存在を認識していることは実測で確認できました。
読まなかったクローラー
同期間に巡回していたPerplexityBot・ClaudeBot・ChatGPT-Userは、llms.txt本体を取得していませんでした。PerplexityBotは記事ページの /llms-txt-guide/ は読んでいるのに、本体は読んでいないという動きです。
| クローラー | 取得件数 | 初回取得日 | 動きの特徴 |
|---|---|---|---|
| AI-Observatory/1.0 | 7件 | 2026年3月18日 | llms.txtのみ単体取得 |
| GPTBot/1.3 | 1件 | 2026年5月8日 | トップページ起点 |
| Googlebot/2.1 | 1件 | 2026年5月10日 | 存在確認 |
| PerplexityBot | 0件 | — | 記事は読むが本体は読まず |
| ClaudeBot | 0件 | — | sitemap起点で巡回 |
| ChatGPT-User | 0件 | — | リアルタイム取得型 |
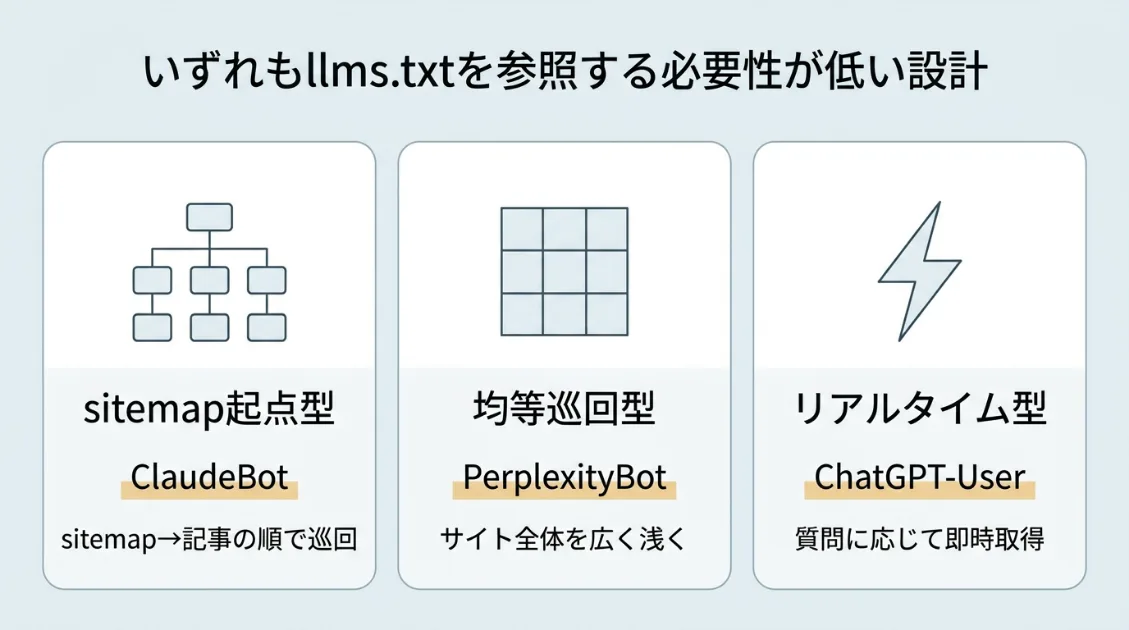
なぜ読まないクローラーが多いのか——3つの巡回型仮説
実測から見えたのは、クローラーごとに情報収集の設計が違うということです。
- sitemap起点型(ClaudeBot):sitemap_index.xmlから全URLを把握できるため、llms.txtを参照する必要性が低い
- 広く浅い均等巡回型(PerplexityBot):サイト全体を自分で読み取りながら判断する設計。案内より自分で読む
- リアルタイム取得型(ChatGPT-User):ユーザー質問のタイミングでその場で取得。事前に構造を把握する必要がない
一方でllms.txtを読んだGPTBotは、学習データ収集を目的とした巡回型。サイト構造を把握してから集める動きのため、llms.txtが手がかりになりやすいと推測できます。
llms.txtがまだ業界標準になっていない
robots.txtはRFC 9309で国際標準化。一方llms.txtは2024年9月提唱で、まだ標準化されていません。クローラー側が優先対応する理由が薄いのが現状です。「意味がない」のではなく「扱いがまだ統一されていない段階」というのが実測からの結論です。
それでもllms.txtを設置する意味——3つの理由
- GPTBot対応として現時点でも有効:ChatGPT系の学習・収集を担うGPTBotは実測で取得を確認。重要ページを整理して伝える入口として機能する
- AIエージェント時代への先行対応:自律的に巡回するエージェントが、Markdownの案内ファイルを手がかりに必要な情報へ到達しやすくなる可能性
- 設置コストが低い:Markdown1枚をルートに置くだけ。標準化が進んだ後に慌てるより、観測データを貯めながら運用するのが合理的
llms.txtの書き方【テンプレコピペOK】
AI観測ラボで実際に使っている書き方を公開します。これをコピーして、あなたのサイト情報に書き換えて使ってください。
# サイト名・サービス名
> サイトを一言で説明する文章を150文字以内で。業種・強み・誰向けかが分かるように。
## 主要コンテンツ
- [ページタイトル](https://example.com/important-page-1/) - このページが何を解決するかを一行で
- [ページタイトル](https://example.com/important-page-2/) - 同上
- [ページタイトル](https://example.com/important-page-3/) - 同上
## 重要カテゴリ
- [カテゴリ名](https://example.com/category/) - どんな記事がまとまっているか
## About
- [運営者情報](https://example.com/about/) - 運営者・目的
## Contact
- [お問い合わせ](https://example.com/contact/)
最終更新: 2026-07-24
WordPressでの設置方法(3分)
- 上のテンプレをテキストエディタに貼り、あなたのサイト情報に書き換える
- ファイル名を
llms.txtにして保存(文字コードUTF-8) - FTPでサーバーのルートディレクトリ(public_html直下)にアップロード
https://あなたのドメイン/llms.txtにアクセスして表示されれば完了
テーマのfunctions.phpで自動生成したい場合は、以下のコードをmu-pluginに追加してください。
add_action('init', function(){
if($_SERVER['REQUEST_URI'] === '/llms.txt'){
header('Content-Type: text/plain; charset=utf-8');
echo "# ".get_bloginfo('name')."\n\n";
echo "> ".get_bloginfo('description')."\n\n";
echo "## Blog Articles\n";
$q = new WP_Query(['posts_per_page'=>10, 'orderby'=>'date']);
while($q->have_posts()){ $q->the_post();
echo "- [".get_the_title()."](".get_permalink().")\n";
}
wp_reset_postdata();
exit;
}
});
まとめ——llms.txtは「置けば読まれる」ではない、でも置く意味はある
- 設置から6週間は誰も読まなかった:置いてすぐ読まれるファイルではない
- 最初に読んだのはAI-Observatory/1.0、次にGPTBot・Googlebot:クローラーごとに対応が分かれる
- PerplexityBot・ClaudeBotは本体を読まず:sitemap起点・均等巡回・リアルタイム型という設計の違いが影響
- それでも設置コスト1枚でGPTBot対応と将来への先行投資になる
llms.txtの状況は今も動いています。AI観測ラボでは引き続きサーバーログを観測し、取得クローラーに変化があればこの記事を更新します。
NEXT OBSERVATION
次はあなたのサイトのllms.txtを観測しませんか?
llms.txtを置いたあと、本当にGPTBotが読んだかどうかは、GA4では分かりません。
AI Kansoku Lab Trackerなら、誰がllms.txtを読んだかを管理画面で自動記録。1月0件だったのが、5月に初めて読まれた——というこの記事のようなドラマを、あなたのサイトでも観測できます。
よくある質問
llms.txtは本当に効果がありますか?
AI観測ラボの実測では、設置から6週間は誰にも読まれませんでしたが、3月にAI-Observatory/1.0、5月にGPTBotとGooglebotが取得しています。PerplexityBotやClaudeBotは期間中取得なしでした。即効性はないですが、GPTBot対応と将来のAIエージェント対応として、設置コスト1枚で先行投資できるのが現時点の位置づけです。
robots.txtと両方必要ですか?
はい、両方設置が推奨です。robots.txtは「来ていい・ダメ」の制御、llms.txtは「何がどこにあるかの案内」で役割が異なります。robots.txtでAllowした上で、llms.txtで重要ページを案内するのが基本設計です。
llms-full.txtも必要ですか?
ブログ・メディア系はまずllms.txtだけで十分です。llms-full.txtは全記事の本文を1ファイルにまとめるため、数百KB〜数MBになりやすく、現時点ではAIクローラーの対応事例も少ないです。ドキュメントサイトやAPIリファレンスのように全文を一括で渡したい場合に検討してください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


