PerplexityBotとは—PerplexityのAIクローラーの仕組みと役割

サーバーログに「PerplexityBot」という文字列が現れたとき、正体がわからないまま放置しているサイト運営者は少なくありません。
PerplexityBotは、AI検索サービス「Perplexity」が運営するWebクローラーです。Perplexityは質問を入力すると、回答とあわせて引用元サイトへのリンクを表示する検索サービスとして利用が広がっています。
AI観測ラボのサーバーログでも継続的な巡回を確認しており、一定周期でまとまったクロールが発生する独特の動きが見えています。記事の後半では、実際のログをもとに巡回パターンも紹介します。
この記事では、Perplexityのサービスの特徴からPerplexityBotの役割・種類・巡回の特徴、robots.txtでの設定方法まで順番に整理します。
この記事でわかること|📖:約7分
- Perplexityがどんなサービスで、ChatGPTと何が違うのか
- PerplexityBotとPerplexity-Userの役割の違い
- 3月・5月の実測ログで見えた巡回パターンの変化
- robots.txtでの設定方法と注意点
Perplexityとは——AI検索サービスの現在地
Perplexity(パープレキシティ)は、2022年12月にアメリカで生まれたAI検索サービスです。GoogleやYahoo!のように検索結果の一覧を並べるだけではなく、ChatGPTのように会話するだけでもありません。
Perplexityは「AIが答えをまとめ、その根拠となるサイトも同時に示す」検索サービスです。
質問を入力すると答えが文章で返ってくる点はChatGPTと似ていますが、大きな違いがあります。回答の根拠となったウェブサイトへのリンクが、回答文の中に番号付きの引用リンクとして表示される設計です。
Googleのようにリンク一覧を並べて終わりではなく、質問に対して文章で直接答えながら情報の出どころも示します。調査やリサーチとの相性がよく、ビジネスシーンでも利用が広がっています。
Perplexityが注目される理由
Perplexityは、回答とあわせて引用元を確認できる使いやすさから、利用者が急速に増えています。
2025年の国内調査では、生成AIサービスの利用者数はChatGPTが1位、Perplexityが約5万3,000UUで2位という結果が出ています。GeminiやClaudeを上回る数字です。世界全体でもアクティブユーザー数は4,500万人を超え、2025年初頭から大きく成長しました。
2024年6月にはソフトバンクとの提携も発表され、日本市場での認知も広がっています。一部の技術者だけが使うサービスではなく、一般のビジネスユーザーにも広がりつつあります。
ChatGPTとの違いはどこか
ChatGPTは回答そのものを得るのに向いている一方で、Perplexityは「情報がどこから来たのか」まで確認しながら使える点が特徴です。回答文の中に引用元リンクが表示されるため、ユーザーは根拠をたどりながら情報を深掘りできます。
サイト運営者の視点で見ると、自社のページがPerplexityの情報収集対象になるという意味があります。その巡回役を担っているのが、次に紹介するPerplexityBotです。
PerplexityBotとは——役割と仕組み
Perplexityが検索結果を返すためには、事前にウェブ上の情報を収集しておく必要があります。その収集作業を担うのがPerplexityBotです。ウェブサイトを自動で巡回してページの内容を取得し、Perplexityの検索インデックスに蓄積していきます。
Perplexity公式ドキュメントには、PerplexityBotの目的について下記の通り記載されています。
PerplexityBot is designed to surface and link websites in search results on Perplexity. It is not used to crawl content for AI foundation models.
つまりPerplexityBotは、AIモデルの学習データを集めるためのクローラーではありません。ユーザーが検索したタイミングで回答の材料として使うための情報を収集するクローラーです。GPTBotがChatGPTのモデル学習用データを集めるのとは目的が異なります。
User-AgentとIPレンジ
サーバーログでPerplexityBotを識別するには、User-Agent文字列を確認します。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)IPアドレスの公式リストは以下のURLで公開されています。
https://www.perplexity.com/perplexitybot.jsonAI観測ラボの実測ログでは18.97.9.96〜103の連番8IPが確認できています。IPだけで判定しようとすると取りこぼしが発生する可能性があるため、User-Agentによる識別を基本にするのが確実です。
User-Agentを使ったクローラー判定の仕組みについてはAIクローラーはIPで判定するな—User-Agentを使うべき理由で詳しく解説しています。
PerplexityBotとPerplexity-Userの違い
Perplexityのクローラーは1種類ではありません。公式ドキュメントには2種類のUser-Agentが明記されています。
| 種類 | 役割 | robots.txt |
|---|---|---|
| PerplexityBot | 検索結果表示のための自動巡回 | 遵守する |
| Perplexity-User | ユーザーの質問に応じたリアルタイム取得 | ユーザーリクエストを優先 |
簡単にいうと、PerplexityBotは「定期巡回する検索用クローラー」、Perplexity-Userは「ユーザーの質問に応じてその場で動くリアルタイムフェッチャー」です。
※リアルタイムフェッチャーとは:ユーザーの操作をきっかけ・タイミングにてWebページを取得しに来るプログラムのこと。事前にサイトを巡回しておくクローラーとは異なり、「誰かが今質問した」瞬間に動きます。
robots.txtへの対応が2種類で異なる
2種類のクローラーで大きく異なるのがrobots.txtへの対応です。
PerplexityBotはrobots.txtを読んでからクロールを開始します。AI観測ラボの実測ログでも、毎回のクロール前にrobots.txtを取得する動きが確認できています。
一方、Perplexity-Userについて公式ドキュメントには次のように記載されています。
Since a user requested the fetch, this fetcher generally ignores robots.txt rules.
ユーザーのリクエストに応じてページを取得する性質があるため、robots.txtの制限よりも、ユーザーの要求を優先して取得する設計です。
PerplexityBotは定期巡回型、Perplexity-Userはユーザートリガー型。この違いを知っておくと、ログの見え方やアクセスの意味がかなり理解しやすくなります。
Perplexity-Userとは何か
Perplexity-Userは、ユーザーがPerplexityに質問を入力したタイミングで動くフェッチャーです。ユーザーの質問に対して、より正確な回答を返すためにリアルタイムでWebページを取得します。
取得したページの内容は、回答生成や引用元リンクの参照先として使われる可能性があります。
Perplexity-UserのUser-Agent文字列は以下のとおりです。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user)IPアドレスの公式リストは以下のURLで公開されています。
https://www.perplexity.com/perplexity-user.jsonAI観測ラボのログでは、現時点でPerplexity-Userの訪問は確認できていません。Perplexity-Userは、URLを指定した質問や特定ページの取得が必要になった場面で動くためです。
AI観測ラボのログで見えた巡回の特徴
AI観測ラボのサーバーログから、PerplexityBotの巡回パターンを2つの時期で観測しています。3月と5月を比較すると、巡回のサイクルや規模に変化が見られました。
3月の観測——来ない日が続いて突然まとまって来る
2026年3月18日〜24日の7日間で、PerplexityBotは合計167件のアクセスを記録しました。ただし訪問があった日は3日だけで、残り4日はゼロです。
| 日付 | アクセス数 | 特徴 |
|---|---|---|
| 3月18日 | 0件 | — |
| 3月19日 | 0件 | — |
| 3月20日 | 130件 | 10分以内に集中 |
| 3月21日 | 0件 | — |
| 3月22日 | 0件 | — |
| 3月23日 | 33件 | 通常巡回 |
| 3月24日 | 4件 | 画像ファイルも取得 |
特に目立ったのが3月20日の動きです。午前10時6分から10時15分までの約10分間に130件が集中していました。IPアドレスを確認すると、18.97.9.96から18.97.9.103まで、連番8つのIPアドレスが同時に動いていました。
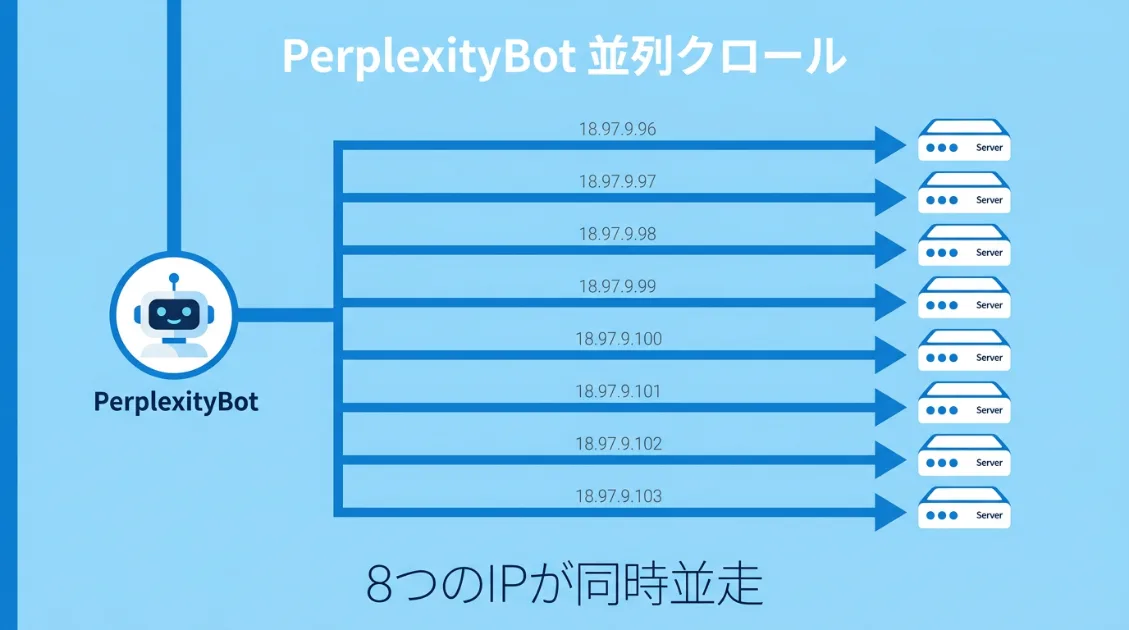
18.97.9.96 18件
18.97.9.97 26件
18.97.9.98 25件
18.97.9.99 4件
18.97.9.100 8件
18.97.9.101 12件
18.97.9.102 10件
18.97.9.103 20件それぞれのIPが別々のページを並行して取得していたため、短時間で大量のページをクロールできています。一般的な検索エンジンの小刻みな巡回とは少し違う、まとまって広く読むタイプの動き方です。
5月の観測——巡回サイクルが短くなった
2026年5月の観測では、巡回のパターンに変化が見られました。
| 日付 | アクセス数 |
|---|---|
| 5月1日 | 54件 |
| 5月2日 | 2件 |
| 5月3日 | 36件 |
| 5月4日 | 2件 |
| 5月5日 | 96件 |
| 5月6日 | 110件 |
| 5月7日 | 11件 |
| 5月8日 | 31件 |
3月は数日空けて一気に来るパターンでしたが、5月は2日ごとに波が来る短いサイクルに変化しています。最大110件と巡回規模も大きくなりました。
3月時点のサイトの記事数は約60本、5月時点では99本です。記事数の増加や更新頻度の変化が、巡回サイクルに影響している可能性があります。
URLの取得傾向——サイト全体を広く巡回する
5月のログで取得URLを確認すると、記事・固定ページ・タグ・カテゴリページが4〜5件ずつほぼ均等に分散していました。特定のページだけに集中するのではなく、サイト全体をまんべんなく巡回する傾向があります。
また/start-guide/・/operator-info/・/glossary/といった固定ページも取得対象に含まれていました。記事本文だけではなく、「このサイトが何を扱っているか」を説明するページも収集対象になっています。
3月の観測では、301リダイレクト済みの旧スラッグURLも取得対象に含まれていました。サイトマップだけではなく、過去のクロール履歴をもとに再訪している可能性があります。URLを変更した場合は、301リダイレクトを正しく設定しておくことが重要です。
PerplexityBotの動きを見ると、特定の記事だけを深く読むというより、サイト全体の構造や主要ページを広く把握しようとする巡回傾向が見えてきます。PerplexityBotが何を取りに来ているのかを知ることは、次に紹介するrobots.txt設定やサイト設計を考えるうえでも大切な視点です。
robots.txtでPerplexityBotを制御する
PerplexityBotはrobots.txtの記述を遵守します。AI観測ラボの実測ログでも、毎回のクロール前にrobots.txtを取得する動きが確認できています。運営方針にあわせて、許可・制限の設定ができます。
許可する場合
多くのサイトでは、PerplexityBotを許可したまま様子を見る設定が一般的です。
robots.txtに何も書かなければデフォルトで許可になります。明示的に許可したい場合は、以下のように記述します。
User-agent: PerplexityBot
Allow: /拒否する場合
PerplexityBotの巡回を止めたい場合は、以下のように記述します。
User-agent: PerplexityBot
Disallow: /特定のディレクトリだけ拒否する場合
会員ページや管理ページなど、一部だけ制限したい場合はディレクトリ単位で指定できます。
User-agent: PerplexityBot
Disallow: /private/
Disallow: /members/複数のAIクローラーをまとめて設定する場合
複数のAIクローラーに同じルールを適用したい場合は、まとめて記述することもできます。
User-agent: GPTBot
User-agent: OAI-SearchBot
User-agent: PerplexityBot
User-agent: ClaudeBot
Disallow: /Perplexity-Userはrobots.txtだけでは制御しにくい
注意したいのはPerplexity-Userです。Perplexity-Userは、robots.txtの制限よりも、ユーザーのリクエストを優先して取得する設計です。
robots.txtにPerplexity-Userを拒否する記述を書いても、完全にアクセスを止められる保証はありません。
User-agent: Perplexity-User
Disallow: /限定公開の情報を守りたい場合は、robots.txtだけに頼らず、パスワード保護やアクセス制限と組み合わせる方が確実です。
整理すると、PerplexityBotはrobots.txtで制御できますが、Perplexity-Userは性質が異なります。Perplexity系のアクセスを正しく理解するには、「定期巡回のBot」と「ユーザー起点の取得」を分けて考えることが大切です。
AIクローラー全般のrobots.txt設定についてはrobots.txt完全ガイド|AIクローラー制御で詳しく解説しています。
PerplexityBotの正体を知ると、サーバーログに現れるアクセスの意味がかなり読み解きやすくなります。AIクローラーの動きは、これからのWeb運営で無視できない観測対象になっていきそうです。
まとめ
PerplexityBotは、AI検索サービスPerplexityがWebサイトを巡回するためのクローラーです。収集した情報はAIモデルの学習ではなく、ユーザーの質問に対する回答生成の参照情報として使われます。
AI観測ラボの実測ログで確認できたPerplexityBotの特徴を整理します。
- 複数のIPアドレスを同時に使った並列クロールで短時間に大量取得する
- 特定のページに集中せず、サイト全体を広く巡回する傾向がある
- 記事・固定ページ・タグ・カテゴリページをまんべんなく取得する
- 記事数や更新頻度の変化に応じて巡回サイクルが変化する可能性がある
- PerplexityBotはrobots.txtを遵守する(Perplexity-Userは別設計)
Perplexityには、自動巡回のPerplexityBotと、ユーザー起点で動くPerplexity-Userという2種類の取得経路があります。アクセスログを正しく読むには、この違いを理解しておくことが大切です。
PerplexityBotがどのようにサイトを読み、どのようなページを参照先として扱うのか——その先の仕組みについては、次の記事でさらに深掘りしていきます。
AIクローラー全体の巡回パターンを比較したい場合はAIクローラーは全員違う動きをしていたもあわせてご覧ください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


