AIクローラーはメタタグを見ているのか?実測ログから考えるページ情報設計

「メタタグを整えればAIに引用されやすくなる」←と書かれた記事をよく見かけます。
たしかに、titleタグやmeta description、OGPなどのメタ情報は、ページの主題を伝えるうえで大切な要素です。
しかしながら、実際にAIクローラーがそれらのメタタグをどのように扱っているかは、公式に細かく明言されているわけではありません。
サーバーログを観測している立場から正直に言うと、「メタタグを整えた=AIに引用される」とは言い切れないのが現状です。
AI観測ラボのサーバーログを確認すると、GPTBot・ClaudeBot・PerplexityBotなどのAIクローラーが、robots.txtを確認したあとに記事HTMLを取得しているケースが見られます。HTMLを取得していることは分かります。
しかし残念ながら、HTML内のメタタグをどこまで評価しているかは、サーバーログだけでは判断できません。
当記事では、実測ログで見えた事実をベースに「AIクローラーはメタタグを見ているのか」を考えながら、サイト運営者として整えておきたいページ情報設計を整理します。
この記事でわかること|📖:約6分
- AIクローラーが
robots.txt確認後にHTMLを取得しているケース(実測ログ) - メタタグがページ情報として果たす本当の役割
- AIクローラーの制御にはメタタグではなく
robots.txtが有効な理由 - title・meta description・OGPで整えるべき具体的なポイント
AIクローラーはどこまでページ情報を見ているのか
AIクローラーが「メタタグを読んでいるか」を直接確認する方法は、現時点ではありません。HTMLを取得したかどうかはサーバーログで確認できますが、そのHTML内のどの要素を評価したかまでは記録されないからです。
しかし、サーバーログからわかることがあります。AIクローラーがページにアクセスする順番です。
AI観測ラボのログ(2026年6月1日)を確認すると、次のような動きが確認できました。
[01/Jun/2026:08:12:28 /robots.txt
[01/Jun/2026:08:12:37 /why-ai-makes-mistakes-chatgpt-perplexity-gemini/
[01/Jun/2026:22:16:32 /robots.txt
[01/Jun/2026:22:16:33 /bytespider-crawler-guide/robots.txtを取得してから、数秒以内に記事ページのHTMLを取得しています。同様のパターンは、GPTBot・ClaudeBot・PerplexityBotなど複数のAIクローラーでも確認しています。
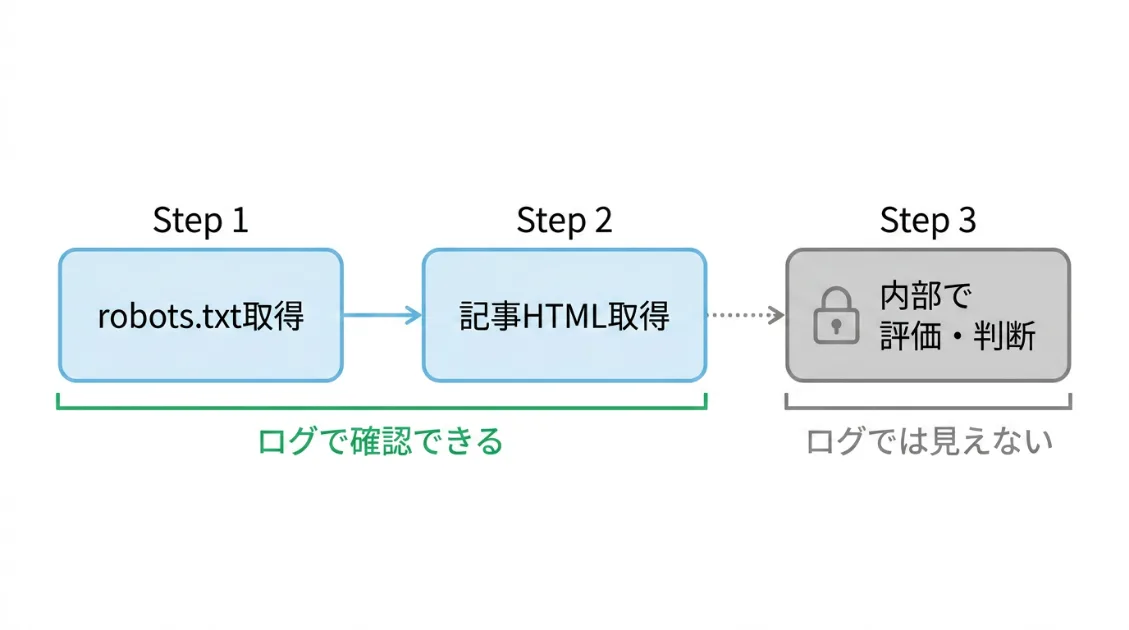
少なくとも今回のログでは、AIクローラーが記事HTMLを取得する前にrobots.txtを確認している動きが見えます。「このサイトのどのページを読んでよいか」を確認してから、記事HTMLを取りに来ていると考えられます。
HTMLを取得しているということは、title・meta descriptionといったメタタグも取得対象に含まれています。ただ、「評価している」かどうかは別の話。少なくとも、メタタグの設定だけでAI引用の可否が決まるわけではありません。
整理するとこうなります。
| ログで確認できること | ログでは確認できないこと |
|---|---|
| robots.txtを取得したか | メタタグを評価したか |
| HTMLを取得したか | どの要素が引用判断に影響したか |
| 訪問した順番・頻度 | 引用するかどうかの内部基準 |
上記前提を踏まえた上で、サイト運営者として整えておくべきページ情報を次のセクションで整理します。
整えるべき基本のページ情報
メタタグがAI引用を直接左右するかは断言できません。が、検索エンジン・AIクローラー・SNSシェアのいずれに対しても、ページの主題を正確に伝えるための基礎情報として整えておく価値はあります。
優先度の高い順に4つ整理します。
① titleタグ——ページの主題を一行で伝える
titleタグはHTMLの中で最も基本的なページ情報です。検索結果のリンクテキストとして表示されるだけでなく、AIがページ内容を把握する際の手がかりにもなります。
整えるポイントはシンプルです。ページごとに異なるタイトルを設定し、30〜60文字を目安に収めます。サイト全体で同じタイトルを使い回している場合は、まずここから直しましょう。
<!-- 良い例 -->
<title>AIクローラーはメタタグを見ているのか? | AI観測ラボ</title>
<!-- 良くない例 -->
<title>AI観測ラボ</title>② meta description——概要を120〜160文字で書く
meta descriptionは検索結果のスニペットとして表示されることがあります。AIがページを要約する際の参考情報になる可能性もあります。ただし、descriptionを書いたからといってAIに引用されるわけではありません。ページの内容を正確に伝えることを目的に書きましょう。
<meta name="description" content="AIクローラーがrobots.txtとHTMLをどの順番で取得しているかを実測ログで確認しながら、サイト運営者が整えておくべきページ情報設計を解説します。">③ canonical URL——正規URLを明示する
同じ内容のページが複数のURLで存在する場合、どれが正規のURLかを検索エンジンに伝えるためのタグです。AIクローラーがcanonicalをどのように扱っているかは明言されていませんが、ページ情報を整理するうえでは確認しておきたい要素です。
WordPressではYoast SEOなどのSEOプラグインが自動で設定してくれることが多いですが、意図しない重複URLが発生していないか確認しておきましょう。
<link rel="canonical" href="https://www.blog.ai-kansoku.com/ai-crawler-metatag/" />④ lang属性——言語を明示する
htmlタグのlang属性で、ページの言語を指定します。日本語コンテンツであればlang="ja"を設定します。WordPressでは通常テーマ側で設定されていますが、確認しておくと安心です。
<html lang="ja">この4つはAI対策というよりも、検索エンジン・AI・SNSのすべてに対して「このページが何について書かれているか」を伝えるための基礎設定です。派手な効果はありませんが、整っていないと損をします。
OGPはAI対策ではなく、共有時の信用設計
OGP(Open Graph Protocol)は、XやFacebookでシェアされたときにタイトル・画像・概要をリッチに表示するための仕組みです。「AI対策としてOGPを設定しよう」という記事を見かけますが、少し違いますね。
OGPの本来の役割は、SNSシェア時にページの情報を正確に伝えることです。ただし、og:titleやog:descriptionはtitleタグやmeta descriptionと内容が一致していることが望ましく、ページ情報を一貫して整える意味では設定しておく価値があります。
設定しておきたい基本のOGPタグ
<meta property="og:title" content="AIクローラーはメタタグを見ているのか?実測ログから考えるページ情報設計">
<meta property="og:description" content="AIクローラーがrobots.txtとHTMLをどの順番で取得しているかを実測ログで確認しながら、サイト運営者が整えておくべきページ情報設計を解説します。">
<meta property="og:type" content="article">
<meta property="og:url" content="https://www.blog.ai-kansoku.com/ai-crawler-metatag/">
<meta property="og:image" content="https://www.blog.ai-kansoku.com/wp-content/uploads/2026/06/ai-crawler-metatag.webp">
<meta property="og:locale" content="ja_JP">記事ページには公開日も入れておく
検索エンジンやAIが情報の新しさを判断する可能性を考えると、記事ページには公開日と更新日を明示しておくと安心です。ただ、日付情報を入れたからといって、AIに引用されやすくなるわけではありません。
<meta property="article:published_time" content="2026-02-02T18:00:00+09:00">
<meta property="article:modified_time" content="2026-06-08T10:00:00+09:00">
<meta property="article:author" content="AI観測ラボ">WordPressではYoast SEOのソーシャル設定からOGPを有効化できます。個別に設定しなくてもtitleとdescriptionを自動で引き継いでくれるので、まずはYoastの設定を確認するのが早いです。
OGPは魔法ではありません。整えることでSNSシェア時の見た目が改善され、ページ情報の一貫性が保たれます。それ以上でも以下でもないと理解しておくと、優先順位をつけやすくなります。
AIクローラーの制御はrobots.txtで考える
旧バージョンのこの記事では、次のような記述がありました。
<meta name="gptbot" content="index, follow">
<meta name="claudebot" content="index, follow">
<meta name="perplexitybot" content="index, follow">上記はAIクローラーを許可する設定として紹介していましたが、正確ではありません。少なくともOpenAIの公式ドキュメントでは、GPTBotやOAI-SearchBotの制御方法として案内されているのはrobots.txtです。メタタグでの制御は標準的な手段として位置づけられていません。
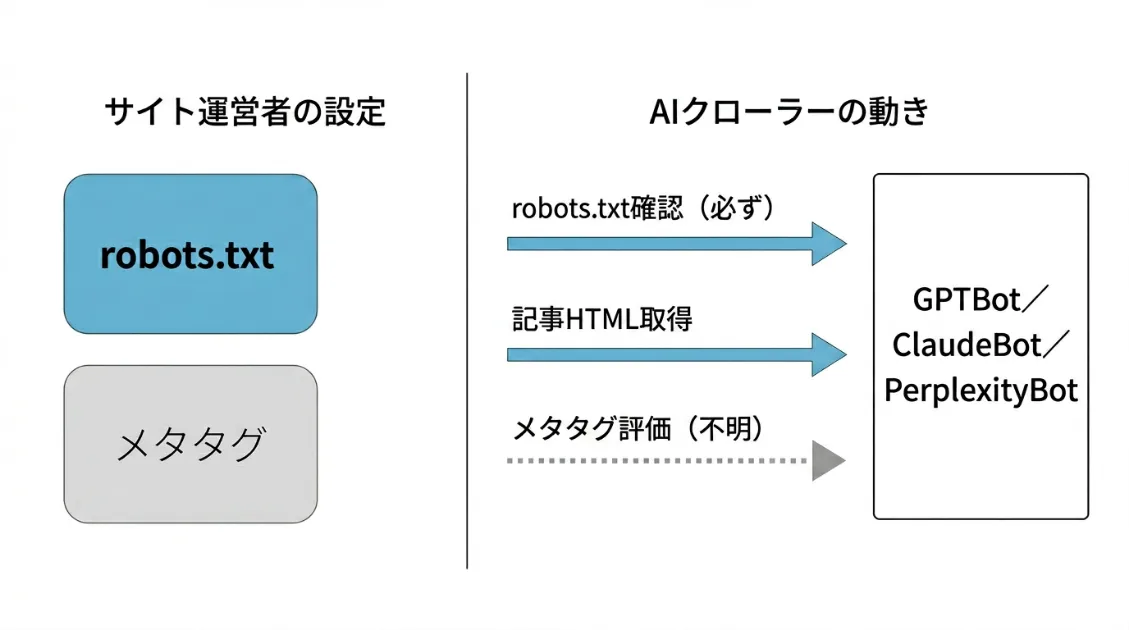
実際にAI観測ラボのログを見ても、AIクローラーがrobots.txtを確認したあとに記事HTMLを取得しているケースが繰り返し見られます。
[01/Jun/2026:05:25:23 /robots.txt ← まず確認
[01/Jun/2026:05:25:31 /gptbot-oai-searchbot-robots-txt-guide/ ← そのあと記事を取得
[01/Jun/2026:09:38:43 /robots.txt ← まず確認
[01/Jun/2026:09:44:37 /gptbot-oai-searchbot-robots-txt-guide/ ← そのあと記事を取得robots.txtを確認してから記事を取りに来る。このパターンが繰り返し確認できるため、少なくともAI観測ラボの実測ログでは、robots.txtがクロール判断の起点になっていると考えられます。
GPTBot・OAI-SearchBot・ChatGPT-Userの違い
OpenAIのクローラーは目的別に分かれています。制御したい目的によってrobots.txtの書き方が変わるため、違いを把握しておきましょう。
| クローラー名 | 役割 | robots.txtでの扱い |
|---|---|---|
| GPTBot | AIモデルの学習データ収集 | 制御できる |
| OAI-SearchBot | ChatGPT検索の検索結果にサイトを表示するためのクロール | 制御できる |
| ChatGPT-User | ユーザー操作をきっかけにしたリアルタイム取得 | robots.txtが適用されない場合がある |
ChatGPT検索に表示されたくない場合はOAI-SearchBotを、学習データへの利用を制限したい場合はGPTBotをrobots.txtで指定します。GPTBotだけをブロックしても、ChatGPT検索への表示を止める設定にはならない点に注意が必要です。
# ChatGPT検索への表示を止めたい場合
User-agent: OAI-SearchBot
Disallow: /
# 学習データへの利用を制限したい場合
User-agent: GPTBot
Disallow: /ClaudeBotも基本はrobots.txtで考える
ClaudeBotなどAnthropic系のクローラーについても、基本的にはrobots.txtでの制御を前提に考えるのが現実的です。ただし、クローラー名や役割は変更される可能性があるため、最新情報は公式情報や実際のサーバーログで確認しておきましょう。
# ClaudeBotを制限したい場合
User-agent: ClaudeBot
Disallow: /robots.txtの詳しい書き方は
robots.txt完全ガイド|AIクローラー制御で解説しています。
メタタグより効果が期待される設定
かれこれ書いてきましたがメタタグはページ情報を伝えるための補助線です。AIに引用されるかどうかをメタタグだけで決めることはできません。むしろ重要なのは、本文そのものがAIや検索システムに誤解されにくい構造になっているかどうかです。
AI観測ラボで観測してきた実測データや、これまでの記事改善の経験をもとに、優先して整えたい要素を4つ整理します。
① 結論をページの冒頭に書く
AIがページ全体をどのような優先順位で処理しているかは、外部からは分かりません。ただ、長い記事では、冒頭で主題や結論を明確にしておく方が、ページ内容を誤解されにくくなります。
「この記事は何について書かれているか」「結論として何が言いたいのか」を冒頭の1〜2段落で明確にしておくことが、AIに正確に理解してもらうための基本です。結論や要点を後半にまとめる構成は、人間には読みやすくても、機械的な読み取りでは不利になる可能性があります。
② 見出し構造を整える
H1・H2・H3の見出し構造は、ページの論理構造を伝える骨格になります。見出しだけを読んでも記事の流れが理解できる状態が理想です。
逆に避けたいのは、装飾目的でH2・H3を使い分けているケースです。見出しレベルが内容の階層と一致していないと、AIや検索エンジンがページ構造を誤解する可能性があります。
③ 更新日・著者・根拠を明示する
AIや検索システムが情報の新しさや信頼性を判断する可能性を考えると、更新日・著者・根拠は明示しておいた方が安全です。特にAI検索や引用では、古い情報と新しい情報が混ざりやすいため、「いつ時点の情報か」を本文中で示すことが重要になります。
AI観測ラボでは記事の公開日・更新日をWordPressの投稿日時で管理し、必要に応じて本文中にも明記しています。「2026年6月時点」のような時点表記を入れておくと、読者にもAIにも情報の前提が伝わりやすくなります。
④ 構造化データで補足する
JSON-LDによる構造化データは、メタタグよりも明示的にページ情報を検索エンジンや機械に伝える手段です。記事の場合はArticleスキーマ、FAQがある場合はFAQPageスキーマを設定しておくと、ページの種類や内容を機械的に読み取りやすくなります。
メタタグ同様、構造化データを入れたからといってAIに引用されるわけではありません。ページの種類・著者・公開日・FAQなどを補足するための情報として考えるのが現実的です。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "AIクローラーはメタタグを見ているのか?実測ログから考えるページ情報設計",
"datePublished": "2026-02-02",
"dateModified": "2026-06-08",
"author": {
"@type": "Organization",
"name": "AI観測ラボ"
}
}
</script>構造化データの詳しい実装方法はJSON-LDはAIクローラーに効くのか—構造化データの種類と実装方法で解説しています。
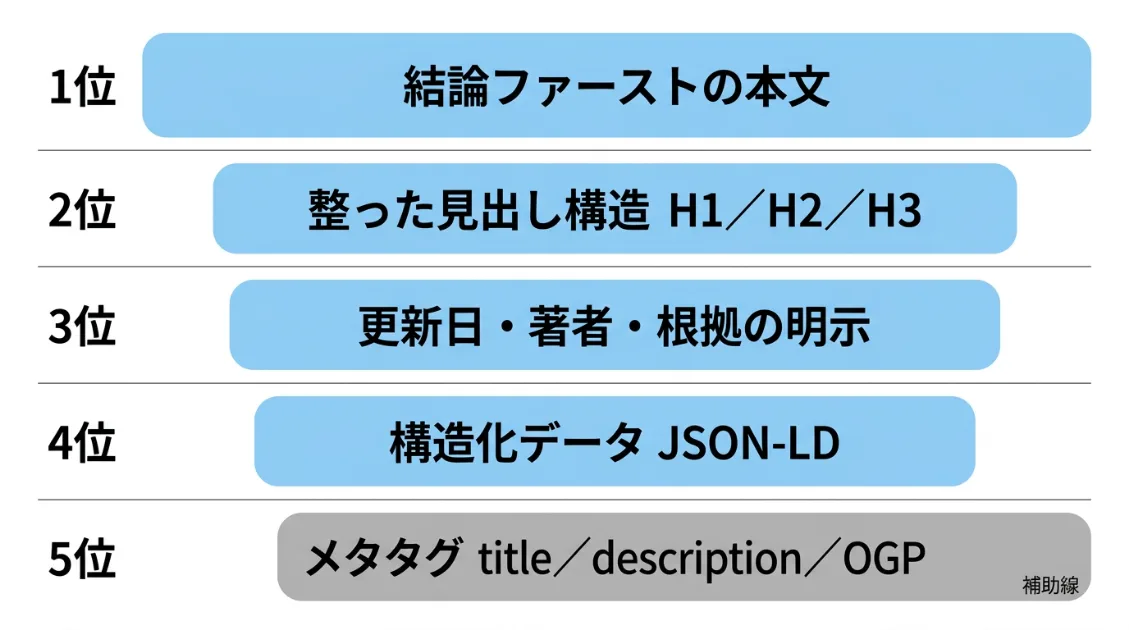
まとめると、メタタグはページ情報の補助線で、AIへの入口を整える役割があります。ただしAIに正確に理解してもらうための本命は、結論ファーストの文章・整った見出し構造・信頼性を示す情報の明示です。
WordPressでの確認ポイント
WordPressを使っている場合、titleやmeta description、OGPなどの基本設定はYoast SEOで管理しやすくなります。だが「入れてあるから大丈夫」ではなく、実際に意図通りに設定されているかを確認する習慣をつけましょう。
Yoast SEOで確認すること
各記事の編集画面下部にあるYoast SEOのパネルで、以下を確認します。
- SEOタイトルが記事ごとに異なる内容になっているか
- メタディスクリプションが120〜160文字で書かれているか
- フォーカスキーフレーズが設定されているか
- ソーシャル設定でOGP画像が設定されているか
一番確認してほしい箇所は、カテゴリーページやタグページのインデックス設定です。Yoast SEOの設定によっては、カテゴリーページやタグページがnoindexになっていることがあります。
AI観測ラボの実測では、カテゴリーページやタグページの設定変更後にクローラーの動きが変わったケースがあります。意図せず重要な一覧ページをブロックしていないか確認しましょう。
👉 カテゴリーページとAIクローラーの関係はタグをnoindexにしたらGPTBotが止まった|Yoast SEO設定の落とし穴で実測データをもとに解説しています。
テーマ側で確認すること
Yoast SEOを使っていても、テーマ側でtitleタグやmeta descriptionを独自に出力している場合、設定が重複することがあります。ページのHTMLソースを開いて、titleタグやmeta descriptionが二重に出力されていないかを確認しておきましょう。
/* ブラウザでHTMLソースを確認する方法 */
Windowsの場合:Ctrl + U
Macの場合:Command + Option + Urobots.txtの設定も合わせて確認する
メタタグの設定と合わせて、robots.txtが意図通りに設定されているかも確認します。Yoast SEOはrobots.txtの編集機能も持っていますが、WordPressの管理画面から直接編集するよりもサーバー上のファイルを直接確認する方が確実です。
/* robots.txtの確認URL */
https://あなたのドメイン/robots.txt👉 robots.txtの詳しい設定方法はrobots.txt完全ガイド|AIクローラー制御で解説しています。
まとめ:メタタグは補助線、本命は別にある
この記事で確認してきたことを整理します。
- AIクローラーはrobots.txtを確認してから記事HTMLを取得しているケースがある(実測ログで確認)
- HTMLを取得していることは分かるが、メタタグをどう評価しているかはログだけでは判断できない
- AIクローラーの制御はメタタグではなくrobots.txtで設定する
- メタタグ(title・description・OGP)はページ情報の補助線として整える価値はある
- AIに正確に理解してもらうための本命は、結論ファーストの本文・見出し構造・更新日や根拠の明示・構造化データ
「メタタグを整えればAIに引用される」という単純な話ではありません。ただし、整えていないと損をする基礎情報でもあります。魔法として期待するのではなく、ページ情報設計の一部として粛々と整えておく、それが現時点での正しい向き合い方だと考えています。
AI観測ラボでは引き続きサーバーログを観測しながら、AIクローラーとページ情報の関係を検証していきます。新しい実測データが出たタイミングでこの記事も更新します。
関連記事
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


