GPTBotはサイトマップばかり読む?サーバーログで見えた記事本文に到達しにくい理由

GPTBotはサイトに毎日来ています。しかし、記事本文にはほとんど到達していません。
サイトマップを確認する、トップページを巡回する、タグページを繰り返し叩く——ログを追うと、GPTBotは記事の「周辺」をひたすら歩き回っているような動きをしていました。llms.txtは無視、Markdownファイルも取得しない。ClaudeBotとはまったく異なる行動パターンです。
AI観測ラボのサーバーログ(2026年4月)に残ったGPTBotの足跡を時系列で追いました。「GPTBotに記事を読んでもらいたいのに来た形跡がない」と感じているサイト運営者に向けて、実測データをもとに行動パターンの正体をまとめます。
※この記事は2026年4月時点のGPTBot/1.2系ログをもとにした観測記録です。その後、GPTBot/1.4ではllms.txtやindex.mdへのアクセスも確認されています。最新の挙動は「GPTBot/1.4で何が変わった?」で整理しています。
この記事でわかること|📖:約6分
- GPTBotが記事本文をほとんど読まない理由とサーバーログで見えた実態
- wp-sitemap.xmlから301リダイレクトで到達するGPTBot特有のsitemap巡回パターン
- llms.txtを無視してトップページのナビから記事を探す意外な行動
- GPTBotに記事本文まで到達してもらうためにやるべきこと
GPTBotとは—OpenAIがChatGPTのために動かすクローラー
GPTBotは、AI企業OpenAIが運営するウェブクローラーです。OpenAIはChatGPT(チャットジーピーティー)というAIを開発している会社で、GPTBotはChatGPTの学習データを集めるためにウェブ上のページを巡回します。
User-Agent(クローラーの名札)は以下の文字列で識別できます。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)GPTBotとよく似た名前のクローラーとして、OAI-SearchBotとChatGPT-Userがあります。役割がそれぞれ異なるため、混同しないよう注意が必要です。
| クローラー名 | 役割 |
|---|---|
| GPTBot | ChatGPTの学習データ収集 |
| OAI-SearchBot | ChatGPTの検索機能向けインデックス収集 |
| ChatGPT-User | ユーザーがChatGPTでURLを送った際のリアルタイム取得 |
3種類の詳しい違いはGPTBotの実測レポートでまとめています。
行動パターン①:wp-sitemap.xmlから301リダイレクトでsitemap_index.xmlに到達する
GPTBotがサイトに来たとき、最初にアクセスするのはrobots.txtです。そのあとサイトマップを探しに行くのですが、ClaudeBotとは探し方が違いました。
実際のログはこうなっています。
GPTBot [18/Apr/2026:09:12:04] GET /robots.txt → 200
GPTBot [18/Apr/2026:09:12:05] GET /wp-sitemap.xml → 301
GPTBot [18/Apr/2026:09:12:05] GET /sitemap_index.xml → 200GPTBotはYoast SEOが生成する/sitemap_index.xmlではなく、WordPressが標準で生成する/wp-sitemap.xmlを最初に探しに行きます。AI観測ラボでは/wp-sitemap.xmlに301リダイレクトを設定しているため、GPTBotは正しく/sitemap_index.xmlに到達できています。
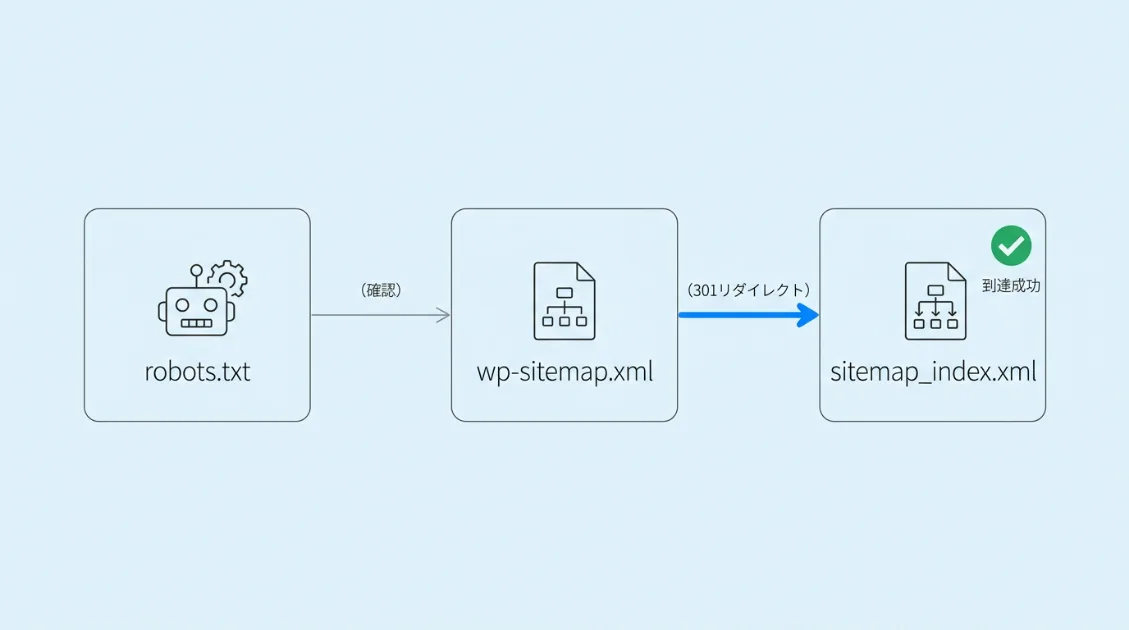
リダイレクト設定がないサイトでは、GPTBotが/wp-sitemap.xmlで404を受け取ってサイトマップを読めないまま終わる可能性があります。WordPressにYoast SEOを使っている場合は、.htaccessに以下を追加しておくと安心です。
RewriteRule ^wp-sitemap\.xml$ /sitemap_index.xml [R=301,L]ClaudeBotは逆に/sitemap.xmlを探して404を踏み続けるパターンでした。同じAIクローラーでもサイトマップの探し方が異なります。ClaudeBotの動きはClaudeBotの行動パターン記事でまとめています。
行動パターン②:トップページのナビから記事を順番に巡回する
サイトマップに到達したあと、GPTBotは記事本文へ直行しません。ログを見ると、トップページのナビゲーションリンクを順番にたどってサイト内を巡回していました。
実際のログはこうなっています。
GPTBot [18/Apr/2026:09:12:06] GET / → 200
GPTBot [18/Apr/2026:09:12:07] GET /ai-crawler/ → 200
GPTBot [18/Apr/2026:09:12:09] GET /ai-search/ → 200
GPTBot [18/Apr/2026:09:12:11] GET /aio-ai-optimization/ → 200
GPTBot [18/Apr/2026:09:12:13] GET /llms-txt-guide/ → 200トップページ(/)を取得したあと、ナビに並んでいる順番通りに記事URLへアクセスしています。サイトマップを読んでいるにもかかわらず、ナビのリンクを起点にした巡回を優先しているように見えます。
サイト運営者への示唆としては、トップページのナビに重要な記事へのリンクを置いておくことが有効だということです。GPTBotに読んでほしい記事はナビやトップページのリンクから到達できる位置に置いておくと、クロールされやすくなります。
行動パターン③:llms.txtを無視する
ClaudeBotはllms.txtを読んだ直後に記事クロールへ進みました。では、GPTBotはどうだったのか——ログを確認すると、7日間でllms.txtへのアクセスは1回もありませんでした。
同じ期間のllms.txtへのアクセスをクローラー別に整理するとこうなります。
| クローラー | llms.txtへのアクセス |
|---|---|
| ClaudeBot | ✅ あり(記事クロールのきっかけに) |
| GPTBot | ❌ なし |
| OAI-SearchBot | ❌ なし |
| PerplexityBot | ❌ なし |
llms.txtはAnthropicのClaudeBotが対応しているファイル形式です。OpenAI系のGPTBotやOAI-SearchBotがllms.txtを参照しているという公式アナウンスは2026年4月時点では確認できていません。
llms.txtを設置すればすべてのAIクローラーに効果があるわけではなく、現時点ではClaudeBotへの効果が実測で確認できている状態です。llms.txtの設置効果と設定方法はllms.txtの書き方・設置手順の記事でまとめています。
GPTBotに記事を読んでもらうには、llms.txtではなくサイトマップとナビゲーション設計の方が有効である可能性があります。
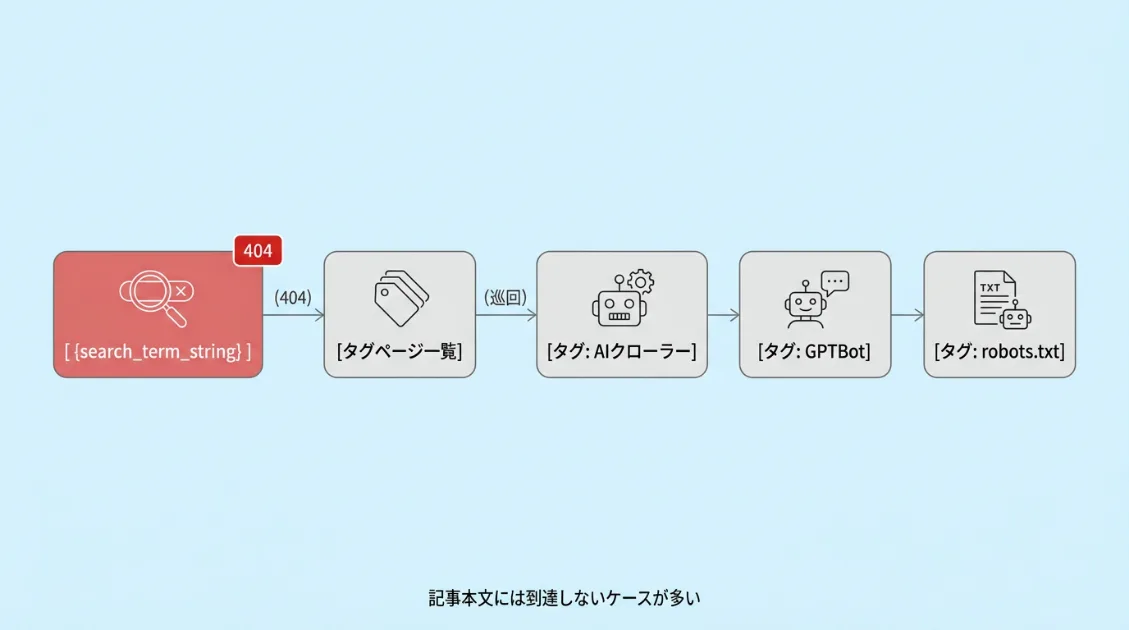
行動パターン④:{search_term_string}というURLからタグページを巡回する
ログの中で原因不明だったのがこの動きです。GPTBotが/tag/%7Bsearch_term_string%7D/というURLにアクセスしていました。デコードすると/tag/{search_term_string}/です。
実際のログはこうなっています。
GPTBot [18/Apr/2026:09:14:22] GET /tag/%7Bsearch_term_string%7D/ → 404
GPTBot [18/Apr/2026:09:14:25] GET /tag/AIクローラー/ → 200
GPTBot [18/Apr/2026:09:14:28] GET /tag/GPTBot/ → 200
GPTBot [18/Apr/2026:09:14:31] GET /tag/robots.txt/ → 200{search_term_string}はWordPressの内部検索で使われるテンプレートタグです。どこかのページのHTMLソースにこの文字列がそのまま出力されていて、GPTBotがリンクとして認識してアクセスした可能性があります。
観察当初{search_term_string}はログではじめてみたので驚愕であり、GPTBot独自の挙動といえます。一番皆様にしってほしいポイントです。
404を受け取ったあとも、GPTBotはタグページの巡回をやめませんでした。タグページを起点に関連記事を芋づる式に発見するという動きはClaudeBotと共通しています。ただしGPTBotの場合、タグページに到達しても記事本文まで進まずタグ一覧の確認だけで終わるケースが多く見られました。
サイト運営者への示唆としては、WordPressのテーマやプラグインが{search_term_string}をHTMLに出力していないか確認することです。存在しないURLへのアクセスが続くとクロールバジェットの無駄遣いになります。テーマのHTMLソースを確認して、不要なテンプレートタグが露出していないかチェックしてみてください。
行動パターン⑤:記事本文への到達が少ない
ここまでの行動パターンをまとめると、GPTBotはサイトマップを確認し、トップページのナビを巡回し、タグページを繰り返し叩いています。では記事本文にはどれくらい到達しているのか——7日間のログで確認しました。
GPTBotのアクセス先をカテゴリ別に集計するとこうなります。
| アクセス先 | 件数 | 割合 |
|---|---|---|
| robots.txt・sitemap系 | 約40件 | 約35% |
| トップページ・カテゴリ・タグページ | 約50件 | 約44% |
| 記事本文 | 約24件 | 約21% |
全アクセスの約8割が記事本文以外に集中しています。ClaudeBotがllms.txtをきっかけに記事を5本連続で取得したのとは対照的に、GPTBotは記事の「周辺」を広く確認してから、ごく一部の記事だけ本文を取得するという動きをしていました。
記事本文に到達したケースを見ると、トップページのナビから直接リンクされている記事か、複数のタグページに登録されている記事が多い傾向がありました。GPTBotに記事本文まで読んでもらうには、記事への導線を複数用意しておくことが有効である可能性があります。
GPTBotとClaudeBotの行動パターンの違いを比較した詳細データはAIクローラーは全員違う動きをしていた【AI実験室#13】でまとめています。
まとめ
GPTBotはサイトに毎日来ています。ただ、アクセスの約8割は記事本文以外——robots.txt、サイトマップ、トップページのナビ、タグページです。
ClaudeBotがllms.txtをきっかけに記事を連続取得するのとは対照的に、GPTBotはサイトの構造を広く確認してから、ごく一部の記事だけ本文を取得する「sitemap巡回型」の動きをしていました。
ログから見えた対策は3つです。
- wp-sitemap.xmlへの301リダイレクト設定——GPTBotが正しいサイトマップに到達できるようにする
- トップページのナビに重要記事へのリンクを置く——GPTBotはナビから記事を探す
- 重要記事を複数のタグに登録する——タグページ経由の記事発見を増やす
llms.txtはGPTBotには現時点で効果が確認できていません。GPTBotへの最適化はサイト構造とナビゲーション設計が起点になります。ClaudeBotとの行動パターンの詳しい比較はClaudeBotの行動パターン記事もあわせて読んでみてください。
なお、この記事で観測した挙動は2026年4月時点のGPTBot/1.2系のものです。その後GPTBot/1.4ではllms.txtの取得やindex.mdへのアクセスも確認されており、サイト構造の読み方が変化しています。最新の動きはGPTBot/1.4の観測記事を参照してください。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


