ChatGPTはどうやって情報を集めているのか|実測ログで見えた裏側

ChatGPTに引用されているサイトと、されていないサイト。何が違うのか気になったことはありませんか。
「良いコンテンツを書けば引用される」という話はよく見かけます。でも、そもそもChatGPTがサイトを見に来ているのかどうか、確認したことはあるでしょうか。
AI観測ラボでは、サーバーログを使ってAIクローラーの動きを継続的に記録しています。2026年5月上半期のログを分析したところ、ChatGPTがrobots.txtを確認し、記事を取得し、内部リンクを辿るまでの流れが具体的に見えてきました。
この記事では「引用されたかどうか」ではなく、「取得されたかどうか」を軸に整理します。引用の有無は外から確認しづらくても、取得の痕跡はサーバーログに残ります。そこから見えた情報取得プロセスをお伝えします。
この記事でわかること|📖:約8分
- ChatGPTが情報を集めるまでの流れ(OAI-SearchBotとChatGPT-Userの役割の違い)
- 2026年5月上半期の実測ログで見えた、ChatGPTの情報取得プロセス
- ChatGPTに取得されやすい記事・されにくい記事の違い
- サイト運営者が今日から確認できること
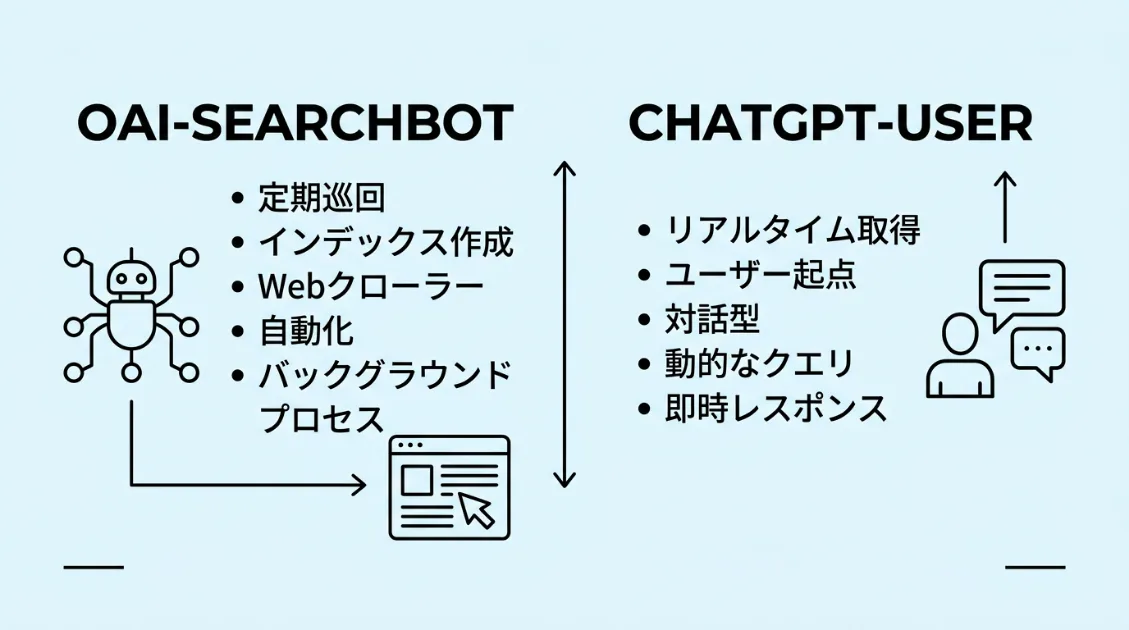
OAI-SearchBotとChatGPT-Userは何が違うのか
ChatGPTは、1つのボットだけで動いているわけではありません。大きく分けると、OAI-SearchBotとChatGPT-Userという2つのボットが存在します。役割がまったく異なるため、混同したまま設定すると意図しない結果になることがあります。
まず役割を整理します。
| ボット名 | 役割 | いつ来るか |
|---|---|---|
| OAI-SearchBot | ChatGPT検索用のインデックス作成 | 定期的に自動巡回 |
| ChatGPT-User | ユーザーの質問に答えるためのリアルタイム取得 | 誰かがChatGPTで質問したとき |
OAI-SearchBotは、あらかじめサイトを巡回してインデックスを作っておくボットです。Googlebotがインデックスを作る動きに近いイメージです。
ChatGPT-Userは、ユーザーがChatGPTで質問したタイミングで動きます。「誰かが今まさに質問している」ときにリアルタイムでページを取得しに来ます。
2026年5月上半期のログでは、同じページに両方が別々のタイミングで訪問しているケースが複数確認できました。どちらが来ているかによって、「定期巡回」なのか「実際のユーザー行動」なのか、意味合いが変わります。
なお、robots.txtでの設定はそれぞれ独立しています。GPTBot(学習用)を拒否していても、OAI-SearchBotを許可していればChatGPT検索の対象になる可能性があります。この3つは別々に制御できます。
詳しい設定方法は以下の記事で解説しています。
→ GPTBot・OAI-SearchBot・ChatGPT-Userのrobots.txt設定ガイド
ChatGPTが情報を集めるまでのステップ
ChatGPTがWeb上の情報を取得するとき、裏側ではいくつかのステップを踏んでサイトを見に来ています。2026年5月上半期のログを整理すると、次のような流れが確認できました。
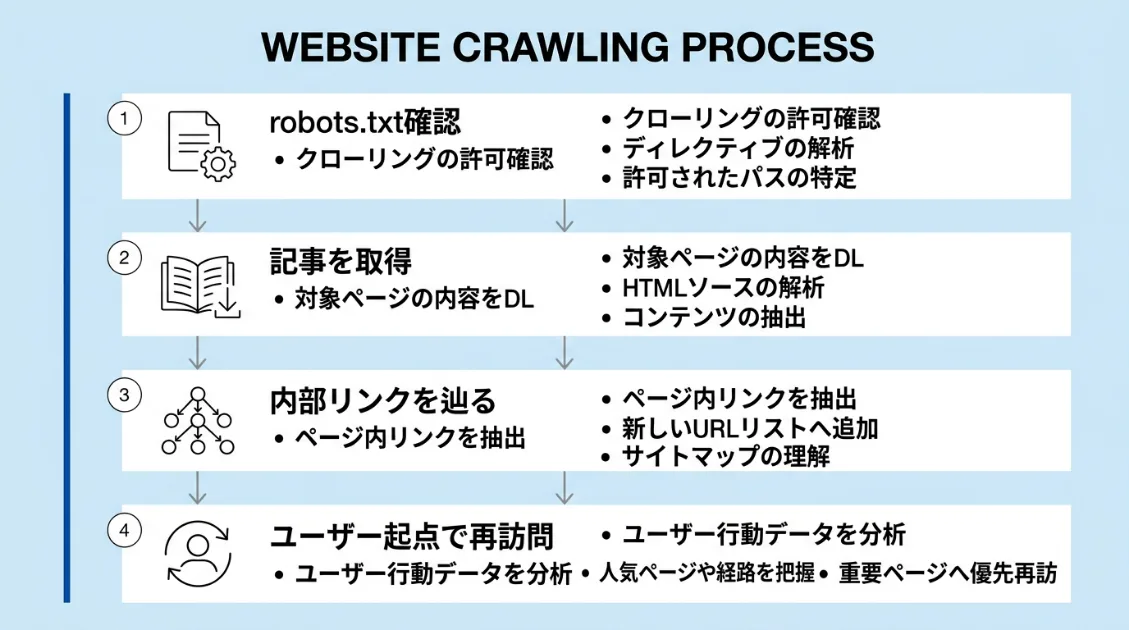
Step1:まずrobots.txtを確認する
OAI-SearchBotは、サイトを取得する前に必ずrobots.txtを確認します。「このサイトはクロールしていいか」を確認してから動く設計です。
観測期間中、同じIPアドレスからrobots.txtだけを繰り返し取得するアクセスが複数回記録されました。記事本文には来ていないのにrobots.txtだけ確認している、という動きです。
robots.txtでOAI-SearchBotを拒否している場合、このステップで止まります。記事がどれだけ充実していても、取得される前に弾かれます。
Step2:許可されていたら記事を取得する
robots.txtで許可されていると確認できたあと、実際にページの取得が始まります。
観測期間中に取得されたページを確認すると、トップページや記事ページへのアクセスが中心でした。タグページや画像ファイルへのアクセスも記録されましたが、記事本文のあるページが優先され、画像単体ページや孤立ページは少ない傾向が見られました。
Step3:内部リンクを辿って関連記事も取得する
1つの記事を取得したあと、その記事内にある内部リンク先も続けて取得する動きが確認できました。
観測期間中のログでは、ある記事を取得してから30秒以内に、内部リンクで繋がった別の記事を複数取得するケースが複数回ありました。単独ページだけを見て終わるのではなく、リンク構造を辿る動きです。
内部リンクが少ないページや、孤立した記事には来にくい傾向も見られました。
Step4:ユーザーが質問するたびにChatGPT-Userが来る
OAI-SearchBotが定期巡回するのとは別に、ChatGPT-Userはユーザーが実際に質問したタイミングで動きます。
観測期間中、同じページに1日に何度もChatGPT-Userが訪問するケースがありました。複数の異なるIPから、同じページへのアクセスが短時間に集中する現象も記録されています。これは、複数のユーザーが同じテーマをChatGPTで検索したタイミングで発生している可能性があります。
ChatGPTに取得されやすいページには共通点があった
観測期間中のログを見ると、ChatGPT-Userのアクセスが特定のページに集中していることがわかりました。すべての記事に均等に来るわけではなく、繰り返し取得されるページとほとんど来ないページに分かれていました。
同じページに1日何度も来る
観測期間中、特定の記事に1日8回以上ChatGPT-Userが訪問するケースがありました。異なるIPアドレスから、同じページへのアクセスが繰り返されています。
複数のユーザーが同じテーマをChatGPTで検索するたびに、そのページが取得対象になっていると考えられます。つまり、「そのページがChatGPT側で繰り返し取得される状態になっている」ことを示している可能性があります。
取得が集中するページの共通点
観測期間中に繰り返し取得されたページを確認すると、いくつかの共通点が見えました。
まず、テーマが明確なページです。「OAI-SearchBotとは何か」「robots.txtの設定方法」など、1つのテーマに絞って書かれたページへのアクセスが多い傾向がありました。
複数テーマをまとめた総合ページより、1テーマ1ページ構造の方が取得されやすい可能性があります。
次に、内部リンクで繋がっているページです。他の記事から内部リンクで参照されているページは、OAI-SearchBotが内部リンクを辿る過程でも取得される機会が増えます。孤立した記事より、サイト内で繋がっている記事の方が取得頻度が高い傾向がありました。
また、robots.txtで明示的に許可されているページも条件のひとつです。取得の前提としてrobots.txtの確認が行われているため、設定が曖昧なサイトより、明示的に許可されているサイトの方が取得されやすい傾向が見られました。
一方で来なかったページ
観測期間中、ChatGPT-UserもOAI-SearchBotも一度も訪問しなかったページも複数ありました。内部リンクが少なくサイト内で孤立している記事、タグページ経由でしか辿り着けない記事などに、その傾向が見られました。
取得されないページは、ChatGPTの検索結果に使われる機会も生まれません。コンテンツの質より前に、「そもそも取得されているか」を確認することが先決です。
ChatGPTに取得される記事とされない記事の違い
「良い記事を書いているのにChatGPTに取得されない」という状況は、コンテンツの質より先に構造的な問題が原因になっていることがあります。観測期間中のログと、AI観測ラボでの設定変更後の変化から見えてきた差を整理します。
robots.txtの設定が起点になる
取得の前提条件はrobots.txtです。OAI-SearchBotはサイトへのアクセス前にrobots.txtを確認します。ここで拒否されていると、記事本文まで到達しません。
観測期間中、robots.txtだけを確認して記事には来ないアクセスが複数記録されました。設定を変更して許可した後、記事への取得が始まるケースも確認しています。
まず確認すべきはrobots.txtで、OAI-SearchBotを許可しているかどうかです。
→ GPTBot・OAI-SearchBot・ChatGPT-Userのrobots.txt設定ガイド
タグページのnoindex設定が影響する
AI観測ラボでは、タグページをnoindexに設定した後、特定のクローラーによる巡回頻度が低下したことをログで確認しています。
タグページは内部リンクの起点になるため、noindex設定によってクローラーが辿るリンク構造が変わります。タグページを通じて記事へ辿り着いていたクローラーが、別のルートを探す動きに変化しました。
タグページの設定は、クローラーの巡回ルートに直接影響します。
→ タグをnoindexにしたらGPTBotが止まった|Yoast SEO設定の落とし穴
内部リンクの有無が巡回ルートを決める
OAI-SearchBotは記事内の内部リンクを辿って関連記事を取得します。内部リンクが少ない記事や、他の記事からリンクされていない孤立した記事には到達しにくい傾向があります。
観測期間中、ある記事を起点に内部リンク先の複数記事が短時間で連続取得されるケースが何度も確認されました。逆に、内部リンクで繋がっていない記事への訪問はほとんどありませんでした。
記事を公開したあと、関連する既存記事からの内部リンクを追加することが、取得される確率を上げる現実的な方法のひとつです。
サイトマップ経由の取得も確認されている
OAI-SearchBotはサイトマップを経由して記事を発見するルートも持っています。robots.txtにサイトマップのURLが記載されている場合、そこから記事一覧を取得して巡回するパターンが観測されています。
サイトマップが正しく設置されているか、robots.txtにサイトマップのURLが記載されているかを確認してください。
→ WordPressのsitemapはAIクローラーに届いているか
取得される・されないの差をまとめると
| 条件 | 取得されやすい | 取得されにくい |
|---|---|---|
| robots.txt | OAI-SearchBotを明示的に許可 | 拒否設定・制御が曖昧 |
| 内部リンク | 複数の記事からリンクされている | 孤立していてリンクが少ない |
| サイトマップ | robots.txtに記載・正しく設置 | 未設置または記載なし |
| タグ・カテゴリ | 巡回ルートとして機能している | noindexで巡回頻度が低下 |
| テーマの明確さ | 1記事1テーマで絞られている | 複数テーマが混在している |
サイト運営者が今日から確認できること
ChatGPTに取得されているかどうかは、特別なツールがなくても確認できます。SEOツールでは見えないケースもあるため、確認の順番と方法を整理します。
まずサーバーログを確認する
一番確実な確認方法はサーバーログです。OAI-SearchBotやChatGPT-Userのアクセスがあれば、ログにUser-Agent文字列として記録されています。
確認するUser-Agent文字列は以下の2つです。
OAI-SearchBot:ChatGPT検索用の定期巡回ボットChatGPT-User:ユーザーの質問起点のリアルタイム取得ボット
Xサーバーなどのレンタルサーバーでは、コントロールパネルからアクセスログをダウンロードできます。ログファイルをテキストエディタで開き、上記の文字列を検索するだけで確認できます。
サーバーログの読み方については以下の記事で解説しています。
→ GA4だけではAI流入は計測できない—サーバーログで補完する方法
robots.txtを確認する
ブラウザのアドレスバーにhttps://自分のドメイン/robots.txtと入力すると、現在の設定を確認できます。
まずは、OAI-SearchBotが拒否されていないかを確認してください。以下のような記述があると、ChatGPT検索の対象から外れる可能性があります。
User-agent: OAI-SearchBot
Disallow: /ChatGPT検索への表示を望む場合は、この記述を削除するか、Allowに変更します。
GPTBot(学習用)とOAI-SearchBot(検索用)は別々に設定できます。学習だけ拒否し、ChatGPT検索には表示される状態にすることも可能です。
内部リンクの状況を確認する
取得されていない記事がある場合、内部リンクが原因のことがあります。公開している記事の中に、他の記事からまったくリンクされていない孤立した記事がないか確認してください。
孤立した記事には、関連する既存記事から内部リンクを1本追加するだけで、巡回ルートに乗る可能性が上がります。
診断ツールで基本設定をまとめて確認する
robots.txt・サイトマップ・メタタグなどの基本設定をまとめて確認したい場合は、AI観測ラボの診断ツールが使えます。URLを入力するだけで、AIクローラーへの対応状況を8項目で診断します。
まとめ:「引用される前に取得される」
ChatGPTに引用されるかどうかより先に、「そもそも取得されているか」を確認することが出発点です。引用の確認は難しくても、取得の痕跡はサーバーログに残ります。
2026年5月上半期の実測ログから見えた取得プロセスをまとめます。
- OAI-SearchBotはrobots.txtを確認してから記事を取得する
- 取得した記事の内部リンクを辿って関連記事も取得する
- ChatGPT-Userはユーザーが質問するたびにリアルタイムで来る
- 取得が集中するページには、内部リンク・robots.txt・テーマの明確さという共通点がある
- 孤立した記事や設定が曖昧なサイトには来にくい傾向がある
コンテンツの質を上げる前に、取得される構造になっているかを確認してください。robots.txtの設定・内部リンクの整備・サイトマップの設置。この3つが整っていない状態では、どれだけ良い記事を書いても、取得される機会そのものが生まれにくくなります。
AIクローラーの動きは短期間でも変化しています。AI観測ラボでは引き続きサーバーログを使って観測を続け、新しい動きが確認できたタイミングで追記していきます。
あなたのサイトは、
AIに見えていますか?
URLを入力するだけで30秒。8項目を自動診断し、優先度別の改善プランを提示します。完全無料・登録不要。


